
1. 관계형 데이터베이스의 등장
1) 관계형 데이터베이스의 개념
- 관계형 데이터베이스는 1970년대 E.F. Codd박사의 논문에서 처음 소개된 데이터베이스입니다.
- 관계형 데이터베이스는 릴레이션(Relation)과 릴레이션의 조인 연산을 통해서 합집합, 차집합, 교집합 등을 만들 수 있습니다.
- 현재 기업에서 가장 많이 사용하는 데이터베이스로 Oracle, MS-SQL, MySQL 등의 다양한 데이터 베이스 관리시스템이 있습니다.
2) 데이터베이스와 데이터베이스 관리시스템의 차이점
- 데이터베이스는 데이터를 어떠한 형태의 자료 구조로 사용하는지에 따라 나누어집니다.
- 데이터베이스 관리시스템은 데이터베이스를 관리하기 위한 소프트웨어를 의미합니다.
- 데이터베이스의 종류는 크게 계층형, 네트워크형, 관계형 데이터베이스 등이 있습니다.
- 계층형 데이터베이스는 트리(tree) 형태의 자료구조에 데이터를 저장하고 관리를 합니다. 일반적으로 컴퓨터 하드디스크에 자료를 저장하는 구조라고 보면 됩니다. 보통 1대N의 관계로 표현합니다.
- 네트워크형 데이터베이스는 오너(owner)와 멤버 형태로 데이터를 저장합니다. 네트워크형은 1대N과 함께 M대N도 가능합니다.
- 관계형 데이터베이스는 릴레이션에 데이터를 저장하고 관리합니다. 표형태로 데이터를 저장한다고 보면 됩니다. 관계형 데이터베이스는 릴레이션을 사용해서 집합 연산과 관계연산을 할 수 있습니다.

- 데이터베이스 관리 시스템(DataBase Manage System)은 계층형 데이터베이스, 네트워트형 데이터베이스, 관계형 데이터베이스 등을 관리하기 위한 소프트웨어를 의미하며, 일명 DBMS라고도 합니다.
- Oracle, MS-SQL, MySQL 등이 바로 DBMS며 모두 관계형 데이터베이스를 지원합니다.
## 이론 문제 확인하기
데이터베이스 종류 중에서 부모와 자식관계를 표현하기 쉬운 데이터베이스는?
1. 계층형 데이터베이스
2. 네트워크형 데이터베이스
3. 관계형 데이터베이스
4. 빅 데이터베이스정답 : 1
- 계층형 데이터베이스는 1대N의 관계이므로 부모와 자식관계를 표현하기 쉽니다.
2. 관계형 데이터베이스의 집합 연산과 관계연산
- 관계형 데이터베이스의 특징은 릴레이션을 사용해서 집합 연산과 관계 연산을 할 수 있습니다.
1) 집합연산의 종류
| 집합 연산 | 설명 |
| 합집합(Union) | - 두 개의 릴레이션을 하나로 합하는 것입니다. - 중복된 행(튜플)은 한 번만 조회됩니다. |
| 차집합(Difference) | 원래 릴레이션에 존재하고 다른 릴레이션에는 존재하지 않는 것을 조회합니다. |
| 교집합(Intersection) | 두 개의 릴레이션 간에 공통된 것을 조회합니다. |
| 곱집합(Catesian product) | 각 릴레이션에 존재하는 모든 데이터를 조합하여 연산합니다. |
2) 관계연산의 종류
| 관계 연산 | 설명 |
| 선택 연산(Selection) | 릴레이션에서 조건에 맞는 행(튜플)을 조회합니다. |
| 투영 연산(Projection) | 릴레이션에서 조건에 맞는 속성만을 조회합니다. |
| 결합 연산(Join) | 여러 릴레이션의 공통된 속성을 사용해서 새로운 릴레이션을 만들어 냅니다. |
| 나누기 연산(Division) | 기준 릴레이션에서 나누는 릴레이션이 가지고 있는 속성과 동일한 값을 가지는 행을 추출하고 나누는 릴레이션의 속성을 삭제한 후 중복된 행을 제거하는 연산입니다. |
## 이론 문제 확인하기
다음 중 관계형 데이터베이스 집합 연산이 아닌 것은?
1. 합집합
2. 곱집합
3. 선택연산
4. 교집합정답 : 3
- 집합연산 : 합집합, 차집합, 교집합, 곱집합
- 관계연산 : 선택연산, 투영연산, 결합연산, 나누기연산
3. 테이블의 구조
- 관계형 데이터베이스는 릴레이션에 데이터를 저장하고 릴레이션을 사용해서 집합연산 및 관계연산을 지워하여 다양한 형태로 데이터를 조회할 수 있습니다.
- 릴레이션은 최종적으로 데이터베이스 관리 시스템에서 테이블(Table)로 만들어집니다.
1) 테이블의 구조 - 그림
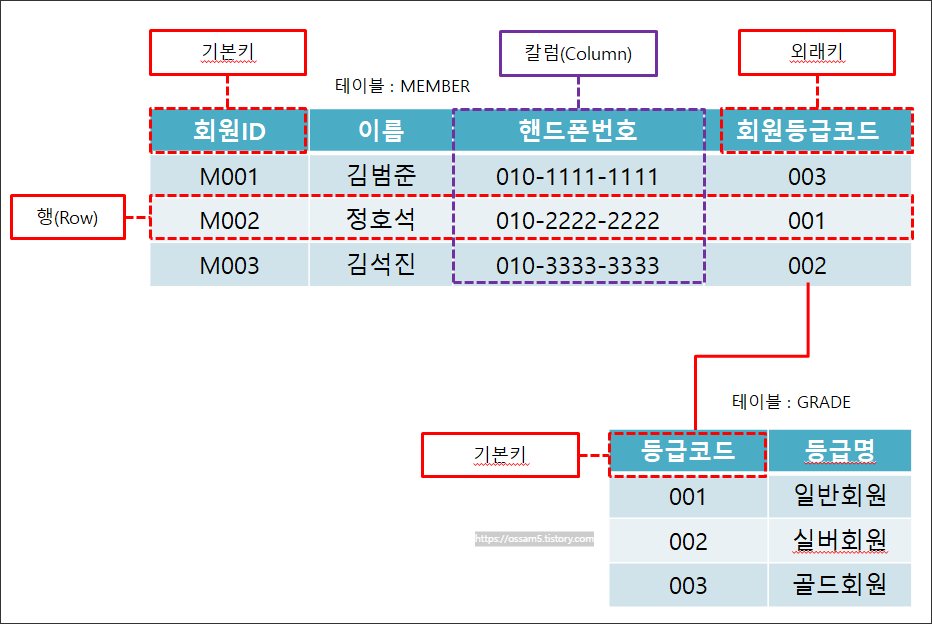
2) 테이블의 요소 명칭
- 테이블은 행과 열(칼럼)으로 이루어집니다.
- 행(Row) : 하나의 테이블에 저장되는 값으로 튜플(Tuple)이라고도 합니다.
- 칼럼(Column) : 어떤 데이터를 저장하기 위한 필드(Field)로 속성(Attribute)라고도 합니다.
- 기본키(Primary Key) : 하나의 테이블에서 유일성과 최소성, Not Null을 만족하면서 해당 테이블을 대표하는 것입니다.
- 외래키(Foreign Key) : 다른 테이블의 기본키를 참조(조인)하는 칼럼입니다. 외래키는 관계 연산중에서 결합연산(Join)을 하기 위해 사용합니다.
'자격증 > SQLD 자격증' 카테고리의 다른 글
| [SQLD자격증강좌] 14강 DDL - 테이블 추가 - 오쌤의 니가스터디 (0) | 2024.03.08 |
|---|---|
| [SQLD자격증강좌] 13강 SQL의 종류 - 오쌤의 니가스터디 (0) | 2024.03.08 |
| [SQLD자격증강좌] 11강 분산데이터베이스 - 오쌤의 니가스터디 (0) | 2024.03.08 |
| [SQLD자격증강좌] 10강 반정규화(De-Normalization) - 오쌤의 니가스터디 (0) | 2024.03.08 |
| [SQLD자격증강좌] 9강 정규화의 문제점과 성능 - 오쌤의 니가스터디 (0) | 2024.03.08 |



